
Поиск и удаление дублей страниц сайта
Наличие дублей негативно влияет на скорость индексирования сайта поисковым роботом. Причина негативного влияние в том, что робот напрасно расходует краулинговый бюджет (по сути это лимит обрабатываемых роботом страниц). На обработку нужных сайту страниц, попросту может не хватить ресурса.
Также может возникнуть ситуация, когда робот по каким-то причинам включил в результаты поиска страницу дубль и произошла смена релевантной страницы. Это может привести к некоторой просадке позиций.
Основные причины появления дублей
- Сайт доступен по 2-м адресам www.site.ru и site.ru. Для устранения данной проблемы необходимо настроить редирект (перенаправление) с одной версии сайта на другую, и указать главное зеркало в robots.txt с помощью директивы host: site.ru.
- Сайт доступен по урлам site.ru/tovar и site.ru/tovar/, то есть со слешем и без. В этом случае необходимо настроить 301 редирект с одних адресов на другие.
- Сайт доступен по таким адресам как site.ru/index.php, site.ru/index.html. Устранить данную проблему можно через редирект или запрет индексации в robots.txt.
- Страницы сайта доступны по параметрическому урлу и по ЧПУ версии. Например страница открывается по адресу site.ru/index.php?=category=80 и по адресу site.ru/noutbuki. Возникает такая проблема при настройке ЧПУ, решается 301 редиректом.
- UTM метки, реферальные ссылки и сессионные переменные. Страница в таком случае доступна по адресу с меткой - site.ru/tovar111/?utm_source=yandex&utm_medium =cpc&utm_campaign=tovar и по адресу без метки site.ru/tovar111/. Все эти метки, реферальные уточнения и сессионные переменные не меняют содержания страниц и соответственно являются дублями. Для удаления подобных дублей из поисковой базы можно использовать атрибут Clean-param в robots.txt.
- Использование HTTP кода 200 на удаленных страницах. Для устранения данной проблемы необходимо корректно настроить 404 код ответ сервера.
Поиск дублей страниц
Google Search Console
Необходимо зайти в Search Console, вкладка «Вид в поиске» → «Оптимизация HTML».

Изучив страницы с повторяющимися тегами title и description можно найти некоторые дубли страниц и предпринять необходимые меры.
Программа Netpeak Spider
Это бесплатный SEO парсер, его можно найти и скачать в свободном доступе. После установки настройте парсер и просканируйте свой сайт. После окончания сканирования нажмите на кнопку «найти дубликаты».
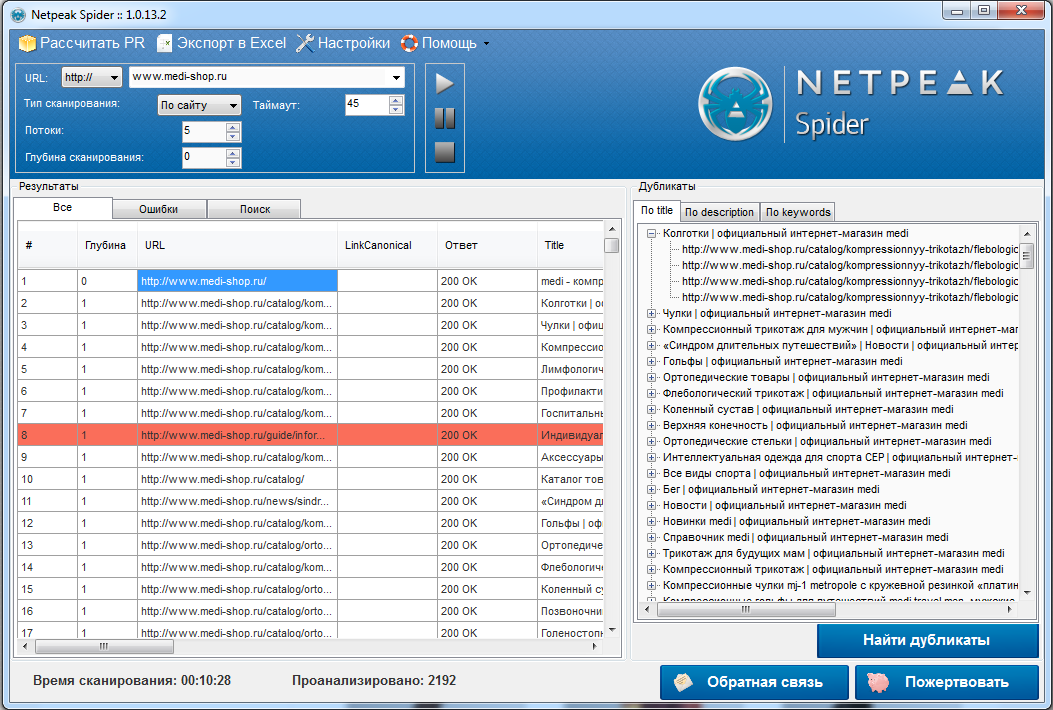
Теперь можно изучать данные сканера, делать выводы. Также есть возможность выгрузки результатов сканирования вместе с дублями.
Программа Comparser
Это платный SEO парсер, я его использую чаще всего при изучении индексации сайта. Этот сканер умеет парсить поисковую выдачу Google и Яндекс и анализировать полученные данные.
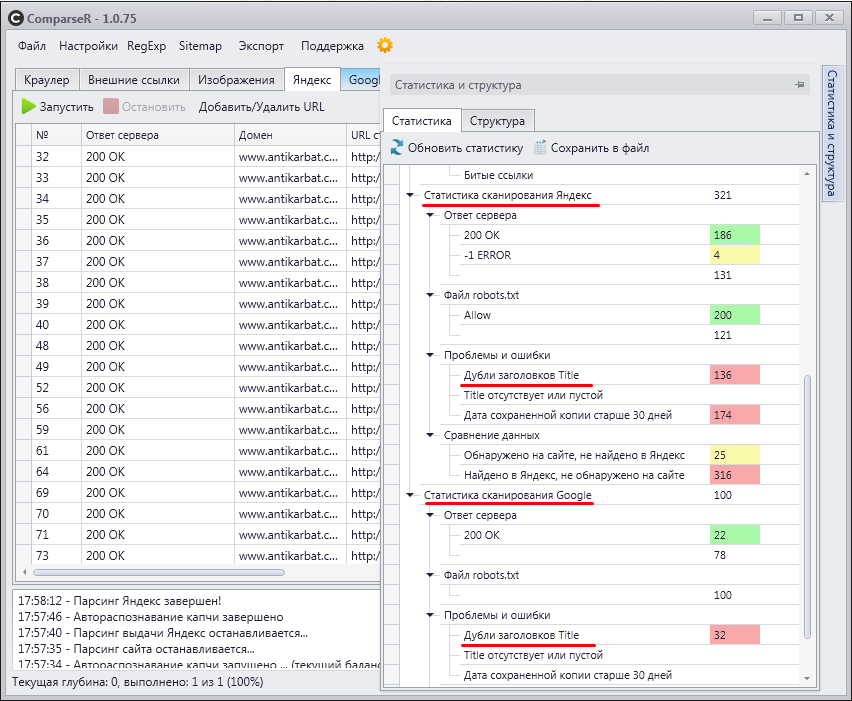
Для изучения возможных дублей необходимо просто кликнуть на строку с информацией.
Поиск по части контента
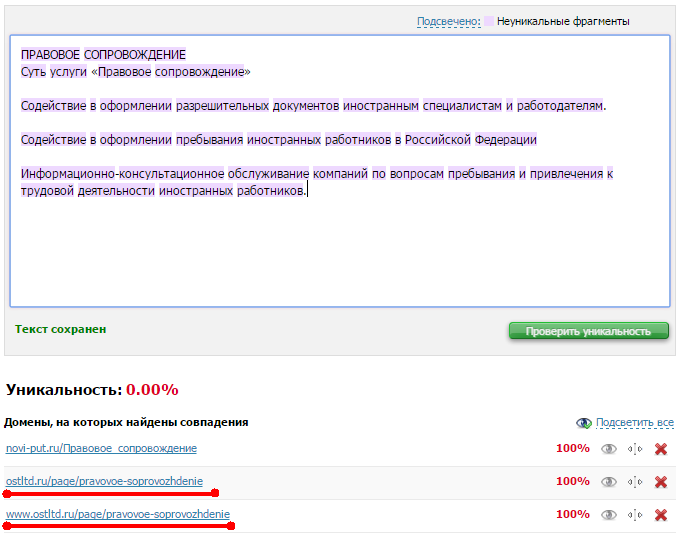
Часто наличие дублей становится открытием при проверке текста с сайта на уникальность. Я пользуюсь сервисом text.ru, и иногда нахожу дубли таким образом.
Дедовский способ
Если ваш сайт не состоит из тысяч страниц, можно использовать запрос «site:site.ru». Этот запрос позволяет увидеть все страницы относящиеся к вашему сайту и проанализировать наличие дублей или каких-то технических страниц в ручную.

В данном примере я не обнаружил дубли, однако наткнулся на недоработку программистов. 404 страница почему-то находится в выдаче и живет там своей жизнью.
Самый лучший способ
К сожалению, я вас не обрадую, самым лучшим способом обычно оказывается применение смекалки и какие-то уникальные методы. Однако в большинстве случаев мне достаточно бесплатного сканера Netpeak Spider, поэтому рекомендую начинать поиск с него.
Способы удаления дублей
Указание канонической страницы
С помощью атрибута rel="canonical" тега <link>, с помощью этого атрибута роботу можно задать каноническую страницу (то есть главную страницу, которая должна находиться в поисковой выдаче). Очень часто данный метод используется для 1 товара в нескольких категориях.
В случае использования данного атрибута пользователю доступны страницы по разным адресам, но поисковая система включает в индекс только каноническую страницу.
Логика использования:
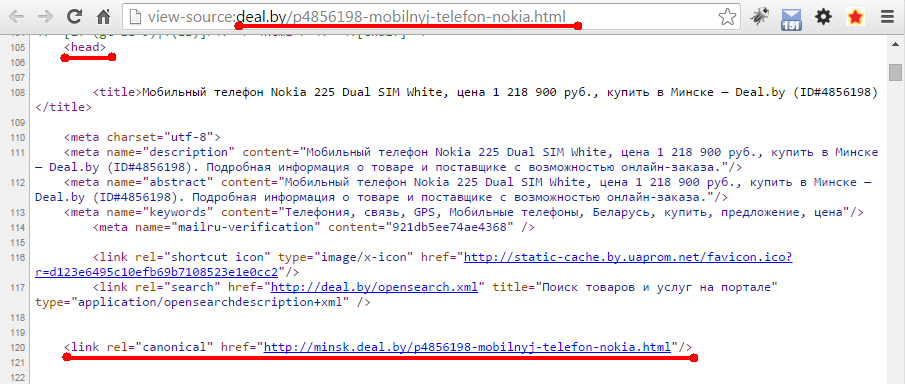
В тэге <head> страницы дубля прописывается строка <link rel="canonical" href="site.ru/category/tovar">. Подчеркиваю, атрибут устанавливается на странице дубле, на канонической никаких атрибутов нет.
301 редирект
Данный способ в большей степени подходит для ситуации с дублями страниц со слешами или без слешей, также его можно использовать для дублей формата site.ru/index.php.
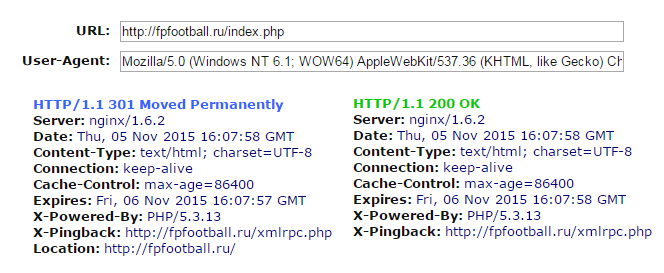
Проверить ответ сервера можно в сервисе www.bertal.ru.
Запрет в Robots.txt
Чаще всего это простые запрещающие правила, в случае с наличием в url страниц каких-либо параметров или переменных, необходимо использовать атрибут Clean-param. О правилах использования этой директивы можно прочитать в инструкциях Яндекса о использовании файла robots.txt.
Просто найти причину появления
Невозможно дать универсальные рекомендации по удалению дублей, так как могут быть индивидуальные и редкие причины появления. Например, наличие календаря новостей с началом датировки в каком-нибудь 1000-ом году (новостей за этот год нет, но страница есть), такая проблема встречается редко, но все же встречается.
Экспериментируйте и задавайте вопросы ниже!
 ИП Шакайло, 2017 ©
ИП Шакайло, 2017 © 

